Track the performance of frontier code agents on BeyondSWE — a comprehensive benchmark evaluating coding agents beyond single bug fixing.
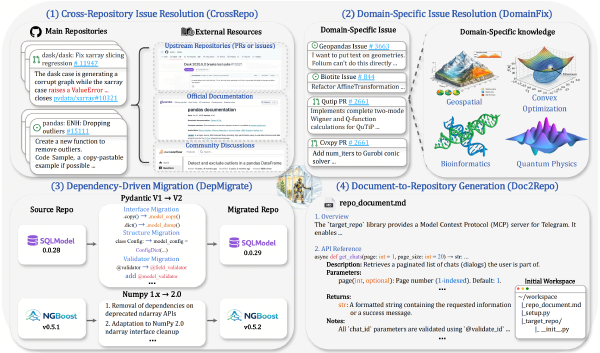
We introduce BeyondSWE, a comprehensive benchmark that broadens existing evaluations along two axes—resolution scope and knowledge scope—using 500 real-world instances across four distinct settings. Together we develop SearchSWE, a framework that integrates deep search with coding abilities to analyse deep research for coding.
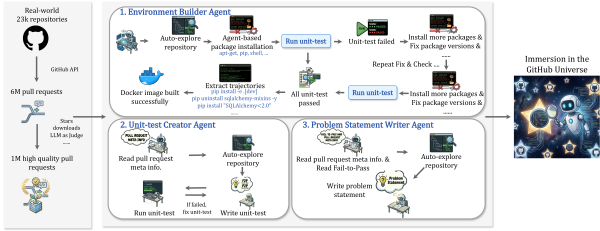
We propose Scale-SWE, a sandboxed multi-agent system that constructs 100k real SWE data points — the largest open-source high-quality SWE dataset to date. By training Qwen3-30A3B-Instruct on distilled data, we achieved 64% on SWE-bench-Verified, surpassing industrial models of the same size.